How They Rig Clinical Trials and The Price We All Pay For It
A practical guide to spotting doctored research and finding the therapies that actually help

Story at a Glance:
Scientific research has provided immense benefit to society, but as its success earned it power, prestige and enormous financing, incentives shifted from advancing humanity to protecting the status quo and ensuring vast profits for the pharmaceutical industry.
We spend more and more on science each year, yet the problems we’ve tasked it with solving remain unsolved, even when solutions already exist. COVID-19 made this painfully clear: dozens of treatments existed for the disease, but rather than utilize them, the medical establishment treated the infection as “incurable” and used that framing to justify a series of counterproductive policies which devastated the economy and left us with a death toll well over a hundred times greater than the poorest nations that did nothing at all.
Central to maintaining this orthodoxy is the belief that large randomized controlled trials (RCTs) must serve as the primary arbiter of scientific truth while other viable and proven research approaches are discarded. While RCTs are sometimes immensely helpful, their data often has minimal clinical relevance to patients yet their dominance displaces all the scientific data which does.
Because large RCTs cost tens of millions of dollars, only a handful of parties can afford to conduct them, which means they are typically done to bring profitable products to market rather than to advance health. Worse, since so much money rides on each trial, perverse incentives always exist to doctor the results so a positive outcome is guaranteed.
Over the years, a robust system of ways to rig trials has emerged, with tactics that exaggerate or fabricate benefits while downplaying or erasing harms. Despite being well recognized, these tactics persist because the regulators and medical journals who depend on the status quo turn a blind eye.
This article provides a concise summary of how trials are routinely rigged, gives you the resources to spot this manipulation and protect yourself from it, and highlights the straightforward solutions that could bring science back to something that prioritizes advancing humanity.
Every medical system in history has been great at addressing certain issues, so-so at others (requiring patients with those issues to see a highly talented practitioner for a successful resolution) and unable to address the rest. For this reason, I’ve long believed the “best” approach to practicing medicine is to develop an in-depth understanding of 1-3 medical systems, and then once you are aware of the therapeutic gaps in your tool box, to recognize when another system has something which can address one of those gaps and fold those approaches into your framework.
In contrast, our society has been conditioned to believe that modern biomedical medicine is the one true system of medicine and that through a robust scientific process, has solved all the previous problems and mishaps which characterized its predecessors (so if any other modality wishes to be used in medical practice it must prove itself by the standards modern medicine has established). However, while that’s a nice-sounding idea, modern medicine is still bound to the same laws which dictate every other medical system, and as such, the reality in healthcare is:
•Conventional medical care is very good at addressing many issues, to the point we take for granted those issues are easily fixable (when for much of history they were not).
•Conventional medicine offers mediocre, less than satisfactory, or highly inconsistent results for many medical conditions large numbers of people suffer from along with it proclaiming that for many illnesses “nothing can be done.”
•A variety of alternative therapies exist which can satisfactorily address many of the areas where conventional medicine fails, but rather than be embraced, they are widely disparaged as pseudoscience and quackery (which has resulted in a thriving alternative medical field that has persisted in the United States despite immense efforts to stamp it out).
To illustrate this point, I’ve focused on DMSO in this newsletter as it has a vast body of literature supporting its safe use for a myriad of challenging conditions. More importantly, due to how dramatic its efficacy is for many “incurable” conditions, I’ve now had thousands of readers submit (currently 6500) almost unbelievable testimonials showing DMSO rapidly cured their ailments (which I have been slowly compiling in articles specific to those ailments).
All of that raises an obvious question; how could a therapy like this remain completely unknown (particularly since in DMSO’s case, scientists, legislators and the public fought the FDA for decades for DMSO to be recognized), especially since the number one concern in healthcare for decades has been reining in its ever-increasing costs?
Note: the reason I continue to emphasize DMSO is that it has been one of the most efficient ways to meet the goals of this newsletter—helping people and providing clear proof of healthcare corruption. In practice, I use many other suppressed modalities that I would like to cover here, but as my time is limited and these articles take a lot of work to write, I have to prioritize where the effort will go the furthest rather than follow my personal interests (which I aim to cover in the future).
RCT Fundamentalism
In a recent article, I put forward the case that there is a very poor cost-to-benefit ratio from the existing clinical trial framework.

The current devotion to randomized controlled trials essentially resulted from:
The FDA interpreting a 1962 Law (designed to prevent the next thalidomide) which stated The H.H.S. Secretary could block any drug from being marketed if it had a lack of “well-controlled investigations” to mean that no drug could be approved for use in the United States unless it had large randomized double-blind trials (RCTs) demonstrating its efficacy (excluding cases where the FDA felt like partially waiving that requirement).
Reformers in the 1990s seeking to address medicine’s longstanding problem with dogmatic and counterproductive ideas persisting—which was done by replacing the existing status quo of deferring to experts with one where medical decisions should be dictated by “the best available evidence,” “individual clinical expertise” and “the patient’s unique values and circumstances.” Sadly, this was rapidly corrupted and switched to only prioritizing “the best available evidence” (e.g., vaccine mandates violate “patient values”) and “the best available evidence” being defined as evidence which met a statutory threshold (large RCTs and “expert” endorsement) rather than the best evidence currently existing on a topic.
Because of this, situations would frequently be encountered where it was clear there was an issue (e.g., a pharmaceutical or vaccine continually injuring someone) or something different needed to be done (e.g., DMSO being used for a debilitating, costly and incurable illness) but those alternative approaches would be blocked because there was no robust RCT supporting their use (and none would ever be done).
Note: DMSO is nearly impossible to conduct a blinded trial on because it produces immediate benefits no other therapy will produce, often causes brief skin irritation or a characteristic odor and will improve areas of the body besides where it was applied. As such, the FDA relentlessly insisted you could not claim the “non-blinded” trials demonstrating DMSO’s efficacy actually constituted proof it worked.
All of this, in turn, results from the fact RCTs have a few critical features most people are not aware of.
First, they are excellent at identifying small data signals which would be nearly impossible for individual practitioners to recognize (e.g., a 3% increase in the risk of a heart attack). This is extremely valuable when there is ambiguity in a routine clinical decision that is regularly made on a large basis each day (as those small differences rapidly add up) or for identifying serious rare side effects from a therapy. However, drug benefits detected in this manner often have very little relevance to routine medical care because they are so small most patients will experience no real benefit from those drugs (and hence why many patients have concluded its a waste of time to visit the doctor for most issues).
Second, while RCTs excel at evaluating pharmaceuticals delivered in standardized doses, they have a fundamental design mismatch with many non-drug therapies. These therapies are often highly individualized and context-dependent, heavily reliant on practitioner skill and the therapeutic alliance, difficult or impossible to blind effectively (with sham controls often proving non-inert), and capable of producing large, rapid, or multifaceted effects that do not align with the ‘small signal’ statistical methods RCTs are optimized to detect in large, homogeneous populations. Moreover, they often rest on holistic diagnostic frameworks and therapeutic philosophies that clash with the reductionist assumptions (and hence the patient allocation and stratification) of the RCT paradigm and success in these systems is frequently defined by outcomes (such as shifts in vitality) that cannot be meaningfully quantified or prioritized within the RCT model. As a result, promising therapies that fall outside the ‘one pill, one disease’ framework are perpetually marginalized, not necessarily because they lack efficacy, but because they cannot readily produce the specific form of evidence the RCT paradigm was designed to generate.
Note: unlike the other medical systems created throughout history, modern medicine does not have a concept of “vitality” or an innate healing force within the body (which I believe underlies why it performs poorly for chronic illnesses).
Third, the placebo effect, combined with the bias introduced when clinical trial observers know a patient is receiving treatment, will make a therapy appear more effective than it actually is. However, what most people do not know is that placebo effect is modest (giving an additional 30-60% improvement) and primarily seen in subjective symptoms (e.g., mood or pain) rather than objective biological shifts (e.g., blood sugar or a tumor size). Likewise, a detailed review found unblinded observers overestimate subjective patient improvements by roughly 36%. This means that while eliminating these biases with RCTs is helpful, it is not always essential.
Fourth, large RCTs are extremely expensive to conduct (typically in the tens of millions of dollars). This introduces three major problems:
•It is only possible for pharmaceutical companies, national governments, and massive NGOs (e.g., The Gates Foundation) to conduct them. Because of this, many topics which should be researched are simply “off-limits” and never researched (e.g., because the tiny amount of money which can be made from an off-patent therapy does not justify a far more costly clinical trial or because they could produce results which threaten a profitable product).
•Because the clinical trials cost so much money to fund, it creates a natural incentive to doctor their results so that a positive outcome can be produced that justifies the massive investment which went into them.
•Because so much money exists in the clinical research field, so many people are invested in the current status quo that they will collectively defend its most egregious abuses while simultaneously reflexively attacking any competing model that challenges their authority over what constitutes valid evidence. Likewise, most biomedical researchers will not pursue controversial topics because producing results that challenge the status quo is economic suicide, cutting them off from the grants they depend on (a tactic Fauci weaponized to silence his critics and hijack science) or any opportunities for the other career path, pharmaceutical industry employment.
In addition to America having poor health outcomes despite vast spending on research and medical care (we spend by far the most but have the worst healthcare amongst the affluent nations), three data points directly dispel the value of RCT fundamentalism.
First, a definitive 2017 Cochrane review found that industry-sponsored drug studies were 34% more likely to report favorable overall conclusions than non-industry-sponsored studies.
Note: other studies have found higher percentages (e.g., 300%), but even at 34%, this means the bias effectively outweighs what these costly studies counteract by addressing the placebo effect.
Second, a definitive 2014 Cochrane Review found that smaller unblinded observational trials typically yielded the same results as large RCTs—which I suspect was due to the fact observational trials are typically only done when the magnitude of an effect is large enough for doctors to notice it (and hence for it to be clinically relevant). This is a critical review, as unlike large RCTs, smaller observational trials are affordable enough that anyone can conduct them, thereby making it possible to break the pharmaceutical industry’s monopolization of medical “truth.”
Note: institutional review processes that were designed to protect research subjects have increasingly become gatekeepers of orthodoxy, making it nearly impossible to obtain approval for even simple human studies on anything deemed controversial (which was incredibly frustrating for me and many others to deal with). This is why so much of the compelling research on therapies like DMSO comes from an era before these barriers existed or from countries where they still don’t.
Third, despite using the best tools science had to offer, spending far more than any other country, and imposing draconian health measures which have destroyed public trust in medicine, the US nonetheless had some of the worst COVID-19 outcomes.
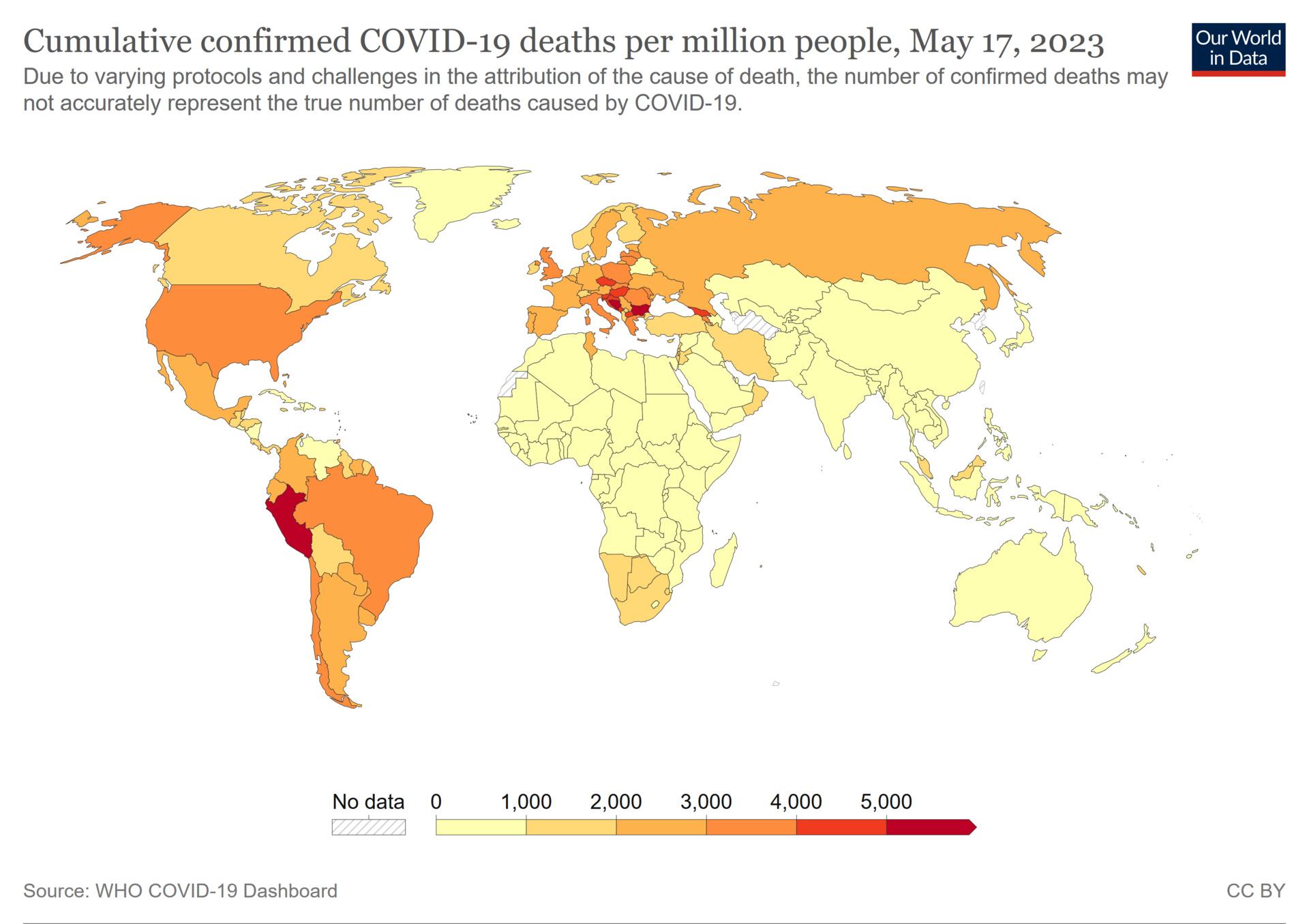
Put differently, many African countries which did virtually nothing for COVID (as they could not afford to) had between a 10-20 per million persons death rate from COVID, whereas the United States recorded 3,625 deaths per million and, beyond its standard medical expenditures, spent roughly $5 trillion in direct appropriations, plus far more in indirect costs from experimental lockdowns and vaccine injuries, triggering a wave of inflation that reached approximately 30% over the last seven years, with housing prices surging 50-60%. This produced the greatest wealth transfer in history to the top 1%, hollowed out the middle class, priced an entire generation out of home ownership, and reduced daily life for millions of Americans into a struggle to simply get by.
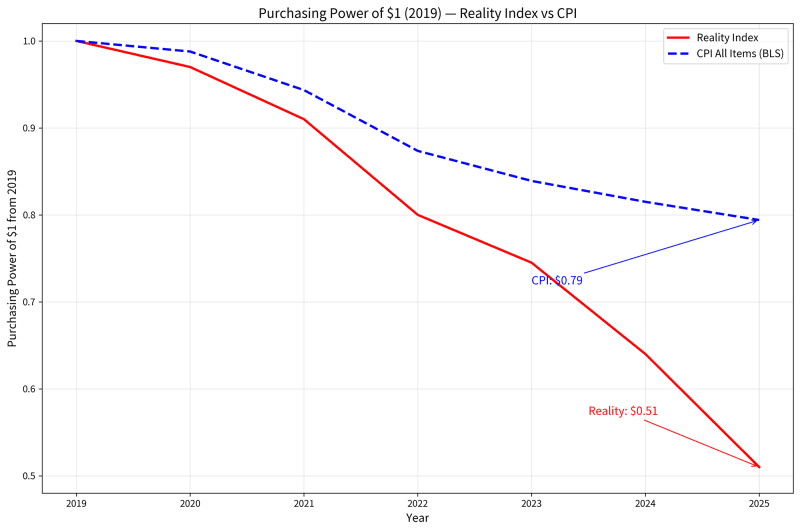
Note: these estimates are likely conservative (as statistics are always manipulated to provide politically beneficial economic news). A more robust analysis (the red line) concluded that since 2019, the US has a 5-12% loss in GDP, 1 in 4 white collar workers has had no raise, and the dollar has had a 40-50% loss of purchasing power.
That’s appalling, particularly since all of it could have been prevented if effective treatments had existed for COVID-19 (e.g., ICU doctors I spoke to in the early days of the pandemic who were being overloaded with COVID-19 all felt the single most important thing to do was create some type of viable early outpatient COVID-19 treatment). However, despite many effective treatments being developed (e.g., in my previous article, I highlighted the simplest and most widely available one, home upper airway disinfection) the standard of care remained “take Tylenol or Ibuprofen [which often made things worse] and come back to the hospital if you can’t breathe.”
Because of this, one group (c19early.org) collaborated to synthesize all the existing data on COVID-19 treatments so an alternative to the government guideline could be available. When I saw one of their charts synthesizing all the available COVID-19 research, a depressing pattern immediately jumped out to me, so I marked the chart up to highlight it:

Essentially, what this showed is that there was no correlation between a treatment’s efficacy and if it ended up in treatment guidelines. Rather, it was primarily a result of how profitable the therapy was (presumably because that propelled the lobbying necessary to get it approved), and more remarkably, the therapies developed by our robust clinical trial process were amongst the worst options available, which in part was due to the fact the committee which created America’s guidelines was selected by Fauci (who’d previously stonewalled every efficacious therapy for AIDS to push AZT through) and nearly everyone Fauci put on it had previously taken money from remdesivir’s manufacturer.
Note: in the previous article here, I documented how every year since 1976, the government has hyped a viral pandemic and has now funneled billions upon billions into proprietary countermeasures that failed—which has persisted because no one is ever held accountable for any of it. This year marks the fiftieth anniversary of that enterprise.
In short, RCTs are an incredibly useful tool for deducing truth, but the moment you rely upon them as the only tool for discerning truth and guiding clinical decisions, many medical problems will rapidly become unsolvable. Because of this, anyone trying to unravel a medical puzzle or find out how to best address a medical ailment has to adopt an incredibly discerning eye to know what can and can’t be trusted, and given how frustrating it has been for me to figure out how to do that, I feel it’s just completely unfair for that burden to be put onto people who need answers. No one should need decades of experience untangling fact from fiction in the scientific literature just because the existing framework can’t be relied upon to ensure what gets published is actually true or the thing that’s actually relevant to the situation at hand.
Research Fraud
Since research is time consuming and costly to do, two conflicting priorities must always be navigated, getting accurate results and making the research worthwhile to do—which frequently equates to it producing the results its sponsors need. Because of this, a “cottage industry” has emerged of ways to doctor data so that a study’s conclusion will achieve the desired outcome, and because of this, once you know how to spot these tactics, you will see them employed again and again throughout the scientific literature.
Likewise, this issue extends beyond science. For example, recently I dissected a political poll which was successfully used to undermine MAHA’s vaccine safety agenda as it showed vaccine safety reforms were so unpopular that candidates who broached them would rapidly lose their midterm elections, hence making the only rational option for the White House be to completely end any critical statements or positions on immunization until after the midterms.

However, what makes this story remarkable is that the poll stood in stark contrast to every other data set, as dozens of polls and recent elections showed that vaccine safety reforms were extremely popular with voters and it was actually the candidates who tried to sabotage RFK’s efforts who experienced disastrous elections. Nonetheless, that single poll which flew in the face of everything else (and had numerous methodological issues which would normally make it inadmissible) was the only one that was widely promoted by the media.
When the actual poll was dissected, it was clear the poll was written to prompt respondents (including those with reservations about vaccines) to give responses which then could be interpreted as “pro-vaccine” and through linguistic tricks, to push them to reject candidates who promoted vaccine safety. More remarkably, a secret poll was recently leaked that was conducted by the same pollster immediately prior to the public poll. The private poll, like every other one, found overwhelming electoral support for vaccine safety and freedom of choice. In turn, when the public and private ones were compared, it was very clear the language in the original was carefully altered so that a completely different response could be elicited. In short, this means that the public poll was not conducted to determine how the electorate felt about vaccines, but rather function as an advocacy tool that created the impression voters overwhelmingly rejected vaccine safety initiatives—a situation which sadly also characterizes many clinical trials (as they also prioritize arriving at a foregone conclusion).
Note: shortly after that article was published, the White House issued a remarkable executive order demonstrating a commitment to pivot back to immediately addressing the vaccine safety issue.
In addition to the slim chance that exposing the poll could change the course of the White House, I felt all of this was important to highlight for three reasons:
It showed how consequential doctored research can be, and that in many cases contrary to what you would expect, no robust way exists to correct it (as until we all fought it, that blatantly biased poll which was full of red flags reversed what a large portion of the electorate had vote for).
Once examined, it was very easy to see why its methodological flaws made it a "junk poll” that should never be taken seriously (much in the same way its results were so far off from every other poll that the probability it accurately represented voter sentiments was close to zero).
Some of the strategies used there were identical to those used to doctor scientific research (e.g., preventing inconvenient data points from entering the scientific literature and using early trials to beta test how to structure the pivotal ones so that unwanted data will not appear in them).
Unfortunately, the data manipulation seen in polling is crude and trivial compared to what routinely occurs in clinical trials, where the financial stakes are orders of magnitude greater and, unlike elections, no immediate real-world outcome exists to unmask the deception.
Fortunately, a few doctors have published pivotal books exposing the mechanics of what goes on behind the scenes of pharmaceutical research:
•Former NEJM editor-in-chief Marcia Angell in 2004 (which played a pivotal role in first exposing these tactics)
•Peter C. Gøtzsche in 2013 (who wrote the densest book which best demonstrates how the pharmaceutical industry operates similarly to an organized crime organization) along with his 2015 book which exposed the rampant fraud throughout psychiatry.
•Malcolm Kendrick in 2015 (whose book I most commonly recommend to patients wishing to better understand the subject)
Likewise, John Ioannidis famously showed in his 2005 paper “Why Most Published Research Findings Are False” that in many fields of medicine, the majority (often >50%) of published research claims are likely false due to bias, small samples, and perverse incentives (a problem that is especially severe for industry-funded studies).
Since a concise compiled list of the depressing tactics utilized to doctor research, to the best of my knowledge, does not exist online (or in any medical school curriculum), I decided to do my best to put together a (likely incomplete) list of the common tactics the industry utilizes along with a few examples of some. As books could be written on each of the ones I will discuss in this article (many of which are quite egregious—such as those which intentionally harm patients to inflate a drug’s benefits), for those wishing to learn more than what I share here, consider reading the above books (particularly Kendrick’s or Gøtzsche’s).
How to Rig a Trial
Since the risks and benefits of a therapy are determined by it having a “statistically significant” improvement from the comparison group (e.g., those receiving placebo), trials are typically gamed by:
•Making the placebo group do worse, so that by comparison to that artificial baseline, the treatment appears better than it is.
•Finding ways to inflate the positive effects reported for the treatment and eliminate the negative ones.
•Finding ways to cast the results obtained in a more positive light and creatively downplay the negative ones.
•Sifting through the random statistical variation inherent in any large trial to identify the specific analytical permutations where a “benefit” spontaneously appears, then presenting those selected findings as the definitive result.
•Ensuring that almost everyone only sees the curated presentation of the trial data which makes the drug look as good as possible.
Note: much of this is analogous to flipping lots of coins, but only showing the cases where it came up heads and using that to claim the coin always comes up heads.
Before we go further, I have to emphasize, what I’m describing is not complicated and pretty obvious fraud to anyone who takes a moment to think about it—but nonetheless the regulators completely tolerate it, which I believe is a consequence of us having a “too big to fail” type situation with clinical research where so much money is spent on it and so many people are dependent upon the system, except for the occasional dissident like the doctors I mentioned above, they can’t afford to question it.
Underscoring this, the FDA (the agency responsible for catching trial manipulation), is itself financially dependent on the industry it regulates. Industry user fees now account for nearly 51% of the FDA's total budget (up from roughly 20% in 2007), with pharmaceutical user fees specifically funding 77% of the prescription drug review program. The personnel situation is equally compromised: a 2024 BMJ investigation found that nine of the FDA's last ten commissioners went on to work for or sit on the board of a pharmaceutical company, and a follow-up investigation found every commissioner since 2000 had gone to industry. More broadly, a 2023 study of 766 HHS political appointees found that 38% of FDA appointees exited to private industry (with the CDC and CMS being even higher, at 53-54%). Among the rank and file, a 2016 BMJ study found that 57% of FDA hematology-oncology drug reviewers who left the agency went to work for or consult with the pharmaceutical industry, and a 2018 Science investigation found that 11 of 16 FDA medical examiners who left after working on drug approvals took jobs with the very companies they had recently regulated. Likewise, in the NIH, FOIA litigation revealed that over $2.685 billion in royalty payments flowed from pharmaceutical companies to NIH institutes and scientists between 2010 and 2023 (with over $1 billion of that marked for individual inventors), data Fauci and the NIH had fought to keep hidden for decades until a federal court compelled its release (discussed further here). Not surprisingly, honest scientists who have tried to push back from within have been marginalized, surveilled and driven out: a FDA safety researcher was ostracized by management after his 2004 Senate testimony exposing the Vioxx catastrophe, a group of nine FDA scientists wrote to President Obama that the agency had "ordered, intimidated, and coerced" them to alter their scientific conclusions, and FDA drug reviewer Ronald Kavanagh reported a systematic culture of intimidation and suppression of safety findings. In short, the regulators tasked with holding clinical trials accountable are funded by the companies conducting them, staffed by people whose next career move depends on staying in those companies' good graces, personally enriched by the products they oversee, and hostile to anyone within their ranks who tries to change any of it.
Note: similar massive conflicts of interest have also been documented within the CDC (detailed here).
Lastly, there are likely other forms of data manipulation besides those described here. While some of these approaches are apparent from reading a journal article, because the pharmaceutical industry is allowed to keep their trial data private, many others were only discovered because lawsuits forced pharmaceutical companies to reveal their internal trial records (which likely still downplayed what actually occurred in trial participants) or trial participants and investigators testified to the malfeasance in the trials (which is extraordinarily rare). As such, it is fair to assume the known examples I cite represent the tip of the iceberg and that the same things have been done in various combinations with many other pharmaceuticals that have not received as much scrutiny.
I will now briefly review some of the most commonly recognized ways trials are doctored. Many of these will leave you jaw dropped, but I must again emphasize are standard practice because regulators, medical journals and peer reviewers tolerate them.
Rigging the Trial Design
Comparator rigging — Testing against placebo rather than the best existing treatment, or handicapping the comparator through incorrect dosing, withholding supportive care, mismatched (incorrect) administration, or choosing an outdated or inferior comparator all inflate a tested drug’s benefit. Non-inferiority margins can be set generously so a “me-too” drug passes as “equally effective” to an existing treatment without demonstrating any real advantage. In psychiatry, head-to-head trials routinely overdose older drugs (e.g., haloperidol) to make newer antipsychotics appear safer.1,2,3,4
Reactogenic or “spiked” placebos — Using a control (“placebo”) substance that itself causes adverse effects, masking drug-specific harms by equalizing side effects across all trial groups. In vaccine trials, either an existing vaccine or aluminum adjuvant is typically used as the “placebo,” which effectively hides many of the severe complications they cause (with Gardasil’s trials being a notoriously egregious abuse of a “fauxebo”). This occasionally also occurs in drug trials (e.g., Tamiflu’s placebo causes the same GI symptoms Tamiflu caused1,2).
Cherry-picking participants — Using overly restrictive criteria to exclude patients likely to experience side effects, while simultaneously finding ways to pre-select those most likely to respond (e.g., up to 90% of potential trial participants can be excluded—guaranteeing completely different results once the drug enters the market and actual patients start taking it).1,2,3 In the riskiest phase I safety trials, a parallel problem exists as pharmaceutical companies rely upon a subculture of “professional guinea pigs” (often unemployed, not legally in the country, or economically desperate) who cycle through multiple trials for pay, lying about medical histories and ignoring the required washout periods between trials (that are needed to accurately calculate drug safety and efficacy), producing non-representative safety data.1,2
Structural priming / run-in periods — Weeding out patients who respond poorly to the drug or well to placebo before randomization begins, thereby inflating the apparent drug-placebo difference and hiding many of the injuries that will be seen once the drug enters the market. Many psychiatric trials also enroll patients already taking similar drugs, ensuring only pre-tolerant subjects enter randomization.1,2
Surrogate endpoints — Because it takes a while for many significant improvements in health to occur, things which are believed to lead to a desired improvement are measured instead (e.g., cholesterol, tumor size, blood pressure, frequency of a symptom, performance on a physical test, being tumor free for a few years, having an antibody response to a vaccine) despite often not leading to the desired outcome. Likewise, psychiatric trials rely heavily on subjective symptom scales rather than functional recovery, suicide prevention, or quality of life — and then spin 1–2 point (inconsequential) differences on these scales as clinically meaningful.1,2,3,4
Note: the abuse of surrogate endpoints is one reason why it is so important to prioritize studies that found a difference in deaths between the experimental and placebo groups as this is the one metric which cannot be gamed.
Imperfect blinding — Trials being unblinded is a frequent issue (especially with more toxic drugs with easy to identify side effects), which in turn leads to investigators underreporting treatment failures or side effects (e.g., this was a massive problem in the COVID vaccine trials and likely facilitated much of their “benefit” as many vaccine recipients with COVID like symptoms were not PCR tested for COVID—with an FDA review acknowledging 477 trial participants with COVID symptoms were never swabbed). Even in the better trials, subtle differences in capsule appearance, taste, or side-effect profiles compromise double-blinding. Psychiatric drugs are particularly vulnerable: conspicuous side effects (akathisia, sedation, sexual dysfunction) allow patients and clinicians to guess allocation, and “activated” (energized) patients on the trial drug tend to stay in trials longer than placebo patients.1,2,3
Use of concomitant medications to mask harms — In psychiatric trials, companies routinely encourage investigators to co-prescribe benzodiazepines (or other sedatives) to suppress akathisia, agitation, and violent reactions caused by the trial drug. This hides drug-specific adverse effects (making the tested drug appear safer), while also confounding efficacy results because benzodiazepines themselves can improve anxiety and depression symptoms. Gøtzsche notes this practice was allowed in the majority of antidepressant trials (e.g., 84% in some analyses) and represents a major design flaw that underestimates harms such as suicide and homicide.1
Offshoring — Running trials in developing countries (or with economically disadvantaged populations) not only lowers costs but leads to laxer oversight (which allows greater trial manipulation and data alteration) hence inflating drug benefits.1,2
Non-standard measurement thresholds — Choosing unconventional cutoffs to manufacture a favorable result. In one voriconazole trial, kidney toxicity was reported using a 1.5-fold creatinine increase rather than the standard 2-fold; at the standard threshold, the difference between drugs disappeared entirely.1
Manipulating the Data Mid-Stream
Truncating observation — Ending data collection before adverse trends emerge. The CLASS celecoxib trial published only 6 months of data from 12–15 month trials because the drug’s advantage disappeared with the full dataset. In the VIGOR trial, Merck used an earlier cutoff for cardiovascular events than for GI events without disclosure. The Pfizer COVID vaccine publication relied on roughly two months of post-dose safety data from a trial designed for two-year follow-up. Psychiatric trials are typically kept to 4–8 weeks, thereby preventing long-term harms from appearing in the data (hence facilitating gaslighting of actual patients who experience these effects).1,2,3
Stopping trials early — Halting a trial when interim results happen to look favorable, which exaggerates effects by roughly a quarter.1,2 (as with drugs that have smaller benefits, random statistical variations can allow them to temporarily achieve a positive result, making it prudent to end the trial before it disappears). The Pfizer’s 95% efficacy figure came from an interim analysis after 170 cases; the high interim result led to emergency authorization, after which placebo recipients were vaccinated (as not doing so was deemed “unethical”) ensuring long-term blinded safety data which could have assessed the harms of the COVID vaccine would never exist. In 73% of protocols examined in one review,1 sponsors had the right to stop the trial at any time for any reason.1,2,3
Pre-injuring the placebo arm — Adding adverse events from pre-randomization washout periods (where things like significant SSRI withdrawals occur) to the placebo group but not the drug group (which was documented for paroxetine, sertraline, and fluoxetine trials). In psychiatric maintenance trials, a more systematic version occurs: patients stabilized on a drug are randomized to continue or switch to placebo, but the switch is done via cold-turkey discontinuation (producing withdrawals and severe symptoms such as rebound psychosis, rebound depression, akathisia) that are then counted as “relapse,” making the drug appear essential for long-term use and justifying lifelong treatment. Gøtzsche understandably views that as abhorrent and cites it as the single most consequential deception in psychiatry.1,2
Biased event adjudication — Ambiguous trial data (e.g., was an end point successfully met or was an injury that occurred caused by the drug) is traditionally ruled upon by an independent (and ideally blinded) committee. Since sponsors decide what gets adjudicated, typically they chose the results they want changed and in three major cardiovascular trials, published adjudicated results all favored the sponsor’s drug versus what study site investigators originally reported.1
Sponsor access to unblinded data — In 73% of protocols examined, sponsors (conveniently) had potential control over the trial while it was running through interim analyses or data monitoring committee participation.1,2
Incentivized underreporting of adverse events — Beyond sponsor-level suppression, subjects themselves hide side effects to remain enrolled and collect payment (plus trial sites penalize dropouts) hiding those injuries from the dataset. Compounding this, many trials only report adverse events exceeding a 5–10% threshold (hence erasing many severe reactions). Likewise, since “pre-existing” illnesses are used to account for many reactions which occur from many psychiatric medications, studies which could settle this with healthy volunteers are routinely suppressed1,2 (e.g., one found SSRIs caused akathisia and suicidality in people with no psychiatric illness).
Outright data fabrication — Rare but documented (e.g., Merck Vioxx death reclassifications1,2). Other examples include fabricating patient records, altering dates and eligibility and inventing trial participants.1,2
Note: in theory, it would be much easier to simple fabricate data than go through all the games described here. However, as far as we know, that is much rarer than the “soft” fraud routinely used, in part because real penalties exist for fabricating data (which to some extent is monitored for), and in part because “soft” fraud is nearly always enough to accomplish everything the industry needs. However, it is well-recognized outright data fabrication is significantly more common in India and China.1,2,3,4
Gaming the Analysis
Relative vs. absolute risk framing — If something (e.g., never leaving the house during the summer to avoid being hit by lightning) reduces the risk of a bad outcome from a 2 in a 100,000 risk to a 1 in 100,000 risk, that translates to 0.001% reduction in your risk (making it hard to justify giving up your entire summer to slightly reduce your likelihood of being hit by lightning). However, if you instead compare 2:100,000 to 1:100,000, it now equates to a 50% reduction and hence a “big deal.” Because of this, pharmaceutical companies typically present favorable data as relative improvements (to massively inflate tiny drug benefits) while simultaneously presenting adverse reactions as absolute risks to shrink and minimize them. This is by far the most common tactic the pharmaceutical industry uses to mislead the public (e.g., in the Pfizer trial, needing to vaccinate 119 people to prevent one non-severe case of COVID was framed as the vaccine miraculously being “95% effective”) and because of how effective it is at selling junk, is also commonly used outside of medicine.1,2,3
Outcome switching — Changing what a trial measures after the data has been collected. One review found 63% of published trials altered at least one primary outcome from protocol, 33% introduced an entirely new one, and none acknowledged the change.1,2 In the Pfizer COVID vaccine trial, the criteria for evaluating severe COVID was quietly shifted from after the second dose (used for the primary efficacy endpoint) to seven days after the first, pulling five additional severe placebo cases into the analysis window (a change buried in the appendix)—after with a reduction of severe COVID eventually becoming the primary basis for pushing the vaccine (as all other benefits failed to materialize once it hit the market). Because there is so much random variation in any large trial, there will always be small clinical benefits that spontaneously emerge in one trial that would never be seen again were the trial to be replicated. This is why seeing the benefit researchers expected to see emerge (what was in the original trial protocol) carries so much more weight than whatever unexpected minor benefit happened to appear once the trial was conducted.
Note: analogously, since it is possible to interpret current political events in so many different ways, I prioritize listening to the commentators who provide frameworks which correctly predict future events.Subgroup fishing and p-hacking — When the primary analysis produces no results, industry will often slice data into narrower subgroups or analyze it multiple ways until they find something (where due to random variation) the threshold for statistical significance (a p value less than 0.05) is met. The CLASS trial involved at least 34 post-hoc subgroup analyses not in the original protocol. Phase III trials by smaller sponsors frequently show a suspicious clustering of results just past the p<0.05 threshold. The STAR*D depression “mega-trial” is an extreme example: the claimed 67% cumulative remission rate relied on sequential reanalysis of progressively smaller, non-randomized subgroups; when analyzed by sustained remission, the actual rate was approximately 3%.1,2,3,4
Note: this is also why you frequently see rather odd and very specific benefits ascribed to drugs, particularly “me-too” ones which essentially copy an existing drug to bring a profitable product to market (but need some marketable differentiator to justify approval and profitability).
Composite endpoints — Bundling serious outcomes (death) with trivial ones (minor symptoms) into a single measure (or doing the same with trial benefits), dilutes drug harms and inflates its apparent benefits. The UKPDS diabetes trial’s “12% benefit” was driven mostly by laser eye treatments, not reductions in death or heart attacks.1,2
Disease-specific rather than overall mortality — Reporting fewer heart attacks while total deaths are unchanged (once again prioritizing reporting which ever measure comes up positive). The MRC blood pressure study was spun as a “33% -reduction in fatal strokes” — but there were 9 more coronary deaths, and total mortality didn’t change.1
Dose-response deception — Claiming a linear dose-response relationship while the actual curve plateaus, with negligible gain from higher doses while harms increase linearly (and as such, data are presented without graphs).1
Note: this is a major issue with ever-expanding blood pressure treatment thresholds, as the initial reduction in mortality is assumed to continue, but in reality reverses at the levels we treat to (detailed here).As-treated or per-protocol analysis substituted for intention-to-treat — Excluding dropouts (who often left due to side effects) rather than analyzing all randomized patients. One Swedish review found that in 42 SSRI trials, companies performed both analyses but published only the more favorable per-protocol results rather than intention-to-treat analysis in all but two cases.1,2
Last observation carried forward — When patients drop out, their last recorded measurement is often carried forward in the data as though it persisted. For rimonabant, this method showed 6.4 kg weight loss above placebo; the more honest baseline-carried-forward analysis showed only 1.5 kg — a fourfold exaggeration.1
Association presented as causation — While “correlation is not causation” line is widely used to dismiss anything which threatens the pharmaceutical industry, in clinical research, preferable observational correlations are sometimes framed as causal.1
Ad-hoc hypotheses — When data contradicts the hypothesis, new explanations are invented to protect the core claim rather than revising it (e.g., Merck explained away excess Vioxx heart attacks by claiming the comparator naproxen was “cardioprotective,” a completely unsupported falsehood that was later refuted).1,2
Bundling and splitting trials — Presenting two separate trials with different protocols as one study (e.g., in the CLASS trial), or splitting a single negative trial to make it appear as two (e.g., Glaxo’s study 3291,2 ). Likewise, the NovoSeven trauma trial’s abstract described one trial as “two trials.”1
Theoretical arguments substituted for clinical evidence — When a drug fails to demonstrate superiority, sponsors invoke mechanistic reasoning. For example, Astra-Syntex argued naproxen should be superior to cheaper analgesics because it dampens inflammation yet a factorial trial found it had no effect on edema.1
Note: the”chemical imbalance” theory of depression — invented as a marketing rationale for SSRIs despite no supporting evidence (and existing evidence arguing the opposite) is perhaps the most successful example: a theoretical argument that bypassed the need for clinical proof of benefit, was used for decades to justify mass prescribing and only recently was finally debunked.
Controlling What Gets Published
Burying negative results — Suppressing unfavorable trials while publishing favorable ones multiple times, sometimes with different author lists (again taking advantage of the random variation seen in trials).1,2,3 An FDA analysis of antidepressants found the published effect size was 32% larger than what all submitted trials showed1 and a single olanzapine trial was published 143 times.1
Publication planning as industrial infrastructure — Medical communications companies orchestrate entire “webs of evidence” — abstracts, supplements, case studies, off-label seeding articles — years before a drug launches. For Zoloft, Current Medical Directions (a medical communications company) produced more articles than academic authors, in higher-impact journals, with more favorable profiles.1
Selective center reporting — In multi-center trials, highlighting only sites with favorable results.1
Hiding adverse events — Recoding (changing the diagnosis) of serious harms to obscure them with all sorts of euphemisms sadly is standard practice. Merck removed three heart attacks from a Vioxx publication and reclassified one death as “cause unknown,” and for Gardasil (which had an extremely high injury rate), simply disclosed to the FDA that 49.6% of vaccine participants developed a “New Medical Condition,” 2.3% of which were categorized as “potentially indicative of a systemic autoimmune disorder.” Eli Lilly recoded suicide attempts on Prozac as “overdose” and suicidal ideation as “depression.” Companies claimed SSRIs caused sexual disturbances in only 5% of patients yet an independent study found the true rate was 59%. Glaxo revised its paroxetine withdrawal reaction estimate from 0.2% to 25% — a hundredfold increase — quietly and in small print. In psychiatry, akathisia (a drug-induced restlessness that drives suicide and homicide) is routinely recoded as “agitation” or “anxiety” — reframing a drug side effect as a symptom of the underlying disease.1,2
Note: in the COVID vaccine trials, Maddie De Garay’s crippling, permanent and agonizing pediatric Pfizer injury was labeled as “functional abdominal pain,” Olivia Tesenair’s cutaneous T-cell lymphoma (which was irrefutably linked to Moderna) was labeled as “lymphadenopathy,” and Augusto Roux, who had a pericardial effusion (and likely pericarditis), and despite a negative test and extensive protest for Roulex, was diagnosed by the lead author of Pfizer’s trial with “anxiety” and “COVID-19” (unrelated to the vaccine). Each of these was quite consequential; for example, shortly after the rollout, I noticed unusual cancers occurring next to mRNA injection sites, and at a recent hearing on COVID vaccine induced cancers, one witness highlighted seventy papers detailing hundreds of post-vaccine cancers similar to what I’d observed (e.g., nearby sarcomas) had been reported in the literature1,2—but since Moderna hid Olivia’s case from the trial, our observations were dismissed because there was “no evidence” the mRNA vaccines could do this.
Suppressing numerical data on unfavorable outcomes — Simply removing numbers that show the drug doesn’t work. In Gøtzsche’s own (early) ankle trial at Astra-Syntex, the company’s management removed all numerical data showing naproxen had no effect on edema from the published paper.1
Incomplete trial registration — Despite a 2007 law requiring it, nearly half of trials for some drugs (or their results) go undisclosed, hiding negative results and distorting the evidence base clinicians rely on.1,2,3
Patient-level data denial — As mentioned before, regulators (FDA, EMA) and pharmaceutical companies withhold individual patient-level data, making independent reanalysis impossible. When Gøtzsche obtained some via leaks and legal action, they consistently revealed more harms than the published versions disclosed.1 Similarly, through leaks, FOIA requests and lawsuits, individuals like Aaron Siri and Steve Kirsch repeatedly showed the publications of COVID vaccine injury data greatly overstated vaccine efficacy and safety. Corroberating this, a collaborative forensic audit of the Pfizer C4591001 trial data (obtained through the PHMPT court order) documented 1,203 subjects “lost to randomization” across 108 sites, at least 1,209 adverse events re-qualified to COVID symptoms, delayed reporting of deaths with cardiac signals before the EUA, systematic differences between the Process 1 clinical trial product and the Process 2 commercial product that was never formally compared, and whistleblower testimony corroborating widespread GCP violations.
Publishing in obscure or fabricated journals — Merck published a fabricated journal, the Australasian Journal of Bone and Joint Medicine, designed to look peer-reviewed but serving as a marketing vehicle. Likewise, favorable meta-analyses are placed in specialty journals where they face less scrutiny.1
Spinning the Presentation
Spin in abstracts and conclusions that contradict the data — Even when raw data shows marginal or negative results, abstracts emphasize positive-sounding phrases. In Gøtzsche’s analysis of 196 NSAID comparison trials, 81 conclusions favored the new drug while only one favored the control — but the actual data showed no difference. In Alzheimer’s trials where Vioxx tripled total mortality, the published papers stated the drug was “well tolerated.”1,2,3
Note: it is extremely common for abstracts or conclusions to not match what the data in the study shows. This often occurs either because the data harms the sponsor or because it goes against prevailing dogmas in science and threatens a researcher who publishes it unless they hide the consequential finding within the paper while having the abstract (the only part most people read) say the opposite.
Asymmetric framing of benefits vs. harms — Benefits presented in relative terms (big-sounding percentages), harms presented in absolute terms or dismissed as “not statistically significant” even when the point estimate suggests risk. In a study of 393 Vioxx abstracts, 3.4 times as many commented on GI bleeding as on thrombotic effects (which killed more people than the reduction in fatal NSAID GI bleeds Vioxx was marketed for) before its withdrawal for causing too many fatal thrombotic effects. Likewise, Vioxx’s VIGOR publication devoted two full tables to GI adverse effects but mentioned thromboses only in a few lines of text.1,2,3
Reporting percentages instead of raw numbers — Vioxx’s VIGOR trial reported thrombotic events only as percentages, making it impossible to calculate the true number of events. When Gøtzsche calculated backwards, he found additional events unaccounted for.1
Presenting small differences on large scales without clinical context — The difference between escitalopram and citalopram after 8 weeks was 1 point on a 60-point scale — clinically meaningless — yet presented as significant.1
NNT/NNH selective framing — Highlighting a favorable number needed to treat while omitting or minimizing the number needed to harm, or switching between absolute and relative framing for benefits versus harms to make the risk-benefit ratio appear lopsided.1,2
Statistical significance conflated with clinical relevance — Highlighting tiny differences that reach statistical significance due to large sample sizes while ignoring that they have no practical meaning for patients.1,2
Semantic framing to soften perception of harms — Companies speak of “efficacy and safety” rather than “benefits and harms.” After all 32 participants at a meeting agreed COX-2 inhibitors increase cardiovascular events, the Danish drug agency wrote they “may be associated with a risk” — three hedging terms where the honest version would say the drugs “increase thromboembolic events.” Merck’s subsequent letter to doctors added a fourth hedge.1
Misleading nomenclature implying therapeutic superiority — Terms like “second-generation antipsychotics” and “atypical antipsychotics” imply newer is better. A 2009 meta-analysis of 150 trials found nothing special about the new drugs. “Selective serotonin reuptake inhibitors” was invented by SmithKline Beecham although “there is nothing particularly selective about them.”1
Unretrievable references as window dressing — A study of 287 drug advertisements found that of 125 promotional claims with references, 23 cited “data on file” or inaccessible sources, and 45 of the remaining 102 were not actually supported by the reference cited.1
Inappropriate statistical framing in abstracts — The TORCH trial’s correct factorial analysis showed fluticasone had no effect whatsoever (rate ratio 1.00). But the abstract used only half the patients in a non-factorial comparison, producing a near-significant result that gave clinicians the false impression both of Glaxo’s drugs should be used.1
Controlling the Narrative
Publication and Media Control — Pharmaceutical companies use multiple levers to guarantee favorable publications, such as purchasing thousands of reprints of journal issues containing their studies (a major revenue source for many journals) or through payments to their editors (multiple studies have found half the editors and peer reviewers of premier medical journals had taken pharmaceutical payments1,2,3,4). Once published in a high-impact journal, pharmaceutical companies can reliably count on the mainstream media to amplify the results as definitive truth.
Note: it is nearly impossible to get research which threatens vested interests published in academic journals, and as Senator Johnson highlighted at his recent hearing on mRNA vaccines and cancer, researchers who were able to clear that high bar and published papers on early treatments for COVID or issues with the COVID vaccines subsequently were relentlessly attacked from every direction and then eventually had their papers retracted for spurious reasons (or no reason at all). Likewise, whenever a paper critical of vaccination which cleared the high bar for publication begins being cited, it often is retroactively retracted for unjustified reasons, with Andrew Wakefield’s autism paper being the most noteworthy case, and Miller’s VAERS analysis showing SIDS clusters near vaccination being the most recent (where the editor, when asked, refused to even provide a reason for the retraction).Ghostwriting and sponsor control — Companies write papers and pay academics to attach their names. Internal Pfizer documents stated studies “belong to Pfizer” and data exists to “support marketing.”1 Seventy-five percent of industry-initiated trials in one sample showed ghost authorship.1 Sponsors typically retain data ownership, analysis rights, and publication vetoes.1,2,3
KOL capture and conflicted guideline committees — Key opinion leaders (KOL) with industry ties design trials, sit on guideline committees, and shape consensus (e.g., the NCEP cholesterol guidelines had members with over 70 conflicts of interest).1,2
Note: the NCEP committee (where each member on average took money from six statin manufacturers) recommended “Aggressive LDL lowering for high-risk patients [primary prevention] with lifestyle changes and statins.” When almost the same set of studies were reviewed by a Canadian division of the Cochrane Collaboration without conflicts of interest, they concluded “Statins have not been shown to provide an overall health benefit in primary prevention trials.” hence illustrating that Fauci’s corrupt NIH COVID-19 Treatment Guidelines committee was far from an isolated case.
Lastly, many of the clinical trials built on these tactics are themselves built on preclinical research that is unreliable for independent reasons — flawed animal models that don’t translate to humans (150+ failed antisepsis drugs from mouse models), contaminated or misidentified cell lines (up to 36% of studies affected), inadequate sample sizes and absent randomization in animal studies, and batch effects in genomics data that were artifacts of when samples were processed rather than real biology. Roughly half of preclinical research may be untrustworthy, at an estimated cost of $28 billion per year in the US alone, meaning many clinical trials are doomed from inception — not because of deliberate manipulation, but because they are testing hypotheses generated by irreproducible science. This compounds every downstream tactic listed above.1
Note: a key initiative MAHA’s NIH director is attempting to spearhead is to incentivize scientists to engage in the less glamorous replication research so that it can become possible to identify the erroneous studies contaminating the scientific literature.
Reclaiming Science
The promise of RCTs is that they eliminate the modest improvement sometimes seen from placebo effects and prevent investigators from inflating drug benefits. As this article shows, those gains are vastly outweighed by the sheer number of “acceptable” ways to doctor clinical trials, making positive results effectively a foregone conclusion, guaranteeing sponsors a return on their investment, and securing the funding the entire research enterprise revolves around.
The consequences speak for themselves. We are flooded with therapies of marginal efficacy that drive ever-increasing healthcare spending, enable catastrophes like COVID-19, and leave millions of Americans languishing with chronic debilitating illnesses. Simultaneously, injured patients are continually gaslighted because the medical community has been conditioned to believe pharmaceutical injuries are not real unless clinical trials corroborate them, yet the trials are systematically designed to erase them.
This was underscored by a recent Senate hearing focused on corruption in science, where Senator Ron Johnson walked through many of the points discussed in this article, highlighting the disconnect between treatment efficacy and guideline inclusion, who can afford to run the trials that dictate those guidelines, and what that means for patients who are left in the dark about their options (with an emphasis placed on the chart I annotated above since it concisely illustrates the consequences of the current paradigm).
What then is the solution?
First, while RCTs are invaluable for science, they cannot be the sole arbiter of truth. A standard needs to be put in place which acknowledges the value of the far cheaper observational trials that clinicians in practice can independently conduct. If clinically significant results are obtained through observational trials, they must be viewed as the “best-available evidence” until a more costly large RCT affirms or refutes them. The most efficient tool we have to refine the practice of medicine is allowing clinicians in the field to figure out what works and then have their peers replicate those studies. During the AIDS crisis, doctors in practice found ways to use existing therapies to treat the disease, while academics in their ivory towers (with pharmaceutical partnerships) failed to produce results. Yet, despite Congressional hearings that demanded Fauci stop obstructing what doctors had found worked, he refused and we were eventually left with a toxic drug that worsened rather than improved AIDS. In turn, since both he and the medical system were never held accountable, it was a foregone conclusion the same thing would happen during COVID-19.
Second, something has to change with the regulatory standards that make it impossible to bring a product to market without a large RCT. This could be accomplished by permitting replicated observational trials to earn limited approvals (where insurance is not required to cover the therapy and only claims which do not overtly state the therapy cures a disease are permitted), allowing off-patent therapies with an extensive track record of safety and efficacy to earn that same limited approval, or redirecting the FDA’s regulatory powers towards safety and product quality control rather than assessing efficacy.
Third, data transparency is essential, and we must make it clear that we cannot be required to abide by scientific policies based on obfuscated data we are expected to trust the summaries of. The evidence-based-medicine community has rallied for data transparency for decades, and we all paid the price for the lack of it during the “safe and effective” COVID vaccine roll-out where we were prohibited from seeing any of the actual safety monitoring data. Science’s successes arose from it being self-correcting and open to scrutiny but all of that goes out the window once it turns into a dogmatic process of us accepting what scientific experts tell us to believe about the data.
Most importantly, once you strip away the elaborate constructs used to hide this scientific fraud, it’s quite obvious what’s being done. Previously, we had to rely on courageous academics who would dig into the depths of the research to expose what was happening, making it only possible to expose a very limited slice of the fraud. Thanks to AI, that same process is now very easy to do, and I believe will expose this entire enterprise to the scrutiny it has long hidden itself from.
On that last point, my experience with AI has consistently been that the results you get are directly proportional to what you feed into it. If you ask an open ended question and have it research the topic for you, the answers will be fraught with errors, hallucinations and falsehoods that reaffirm the orthodoxy. If you directly give it the materials you want processed (e.g., the full text of the study, any supplemental materials attached to it, and everything within its entry on clinicaltrials.gov) along with clear instructions for what you want assessed, you will get a good output. A major reason I wrote this article was so there would be an easy way to copy and paste in the common ways clinical trials are doctored, so that you could effectively ask AI “are there any indications the risk benefit ratio of this study was artificially inflated? Please assess this study for each of these and anything else which could bias the conclusion.”
Note: different AIs are better at certain tasks than others. In this article, I compiled my thoughts on the relative merits of the existing options.
AI is a disruptive technology which, amongst other things, is breaking the information monopoly that was created by hiding behind a wall of text most people could not practically decipher. On one hand, this is immensely hopeful for medicine, as that information monopoly has been utilized to prop up countless abhorrent drugs with terrible risk-benefit ratios. Conversely, it is also worrisome, as so much money is on the line that it is virtually inevitable the pharmaceutical industry will find ways to co-opt it so that it does not threaten their profits. For example, it would be very easy for AI to analyze all the electronic health record data we’ve collected to determine the efficacy and harms of each treatment being utilized for medical care, yet this has never been done. The only people I know who tried (years ago) told me they were shut down because the data they obtained directly threatened pharmaceutical interests.
Being aware of this inevitable trajectory, Steve Kirsch has been diligently trying to support the creation of an independent AI (alter.systems) which will not subsequently be co-opted. He recently mentioned that it is excellent for dissecting the flaws and biases within scientific papers, and asked if I would be willing to help promote it so it can get the critical mass to become a viable alternative to the major platforms.
After looking at Alter AI, I concluded it lacks the biases I see in the other engines (as it instead is overtly skeptical towards the pharmaceutical industry) and quite good at breaking a lot of this complex deception down into very simple and blunt descriptions, but is not as well suited for the complex tasks I often engage in which require processing large amounts of data (as it currently lacks the robust infrastructure the large AI companies have). In short, that makes it well-suited for health focused users who just want to know the truth or analyze individual studies (and recently gave me a fairly good breakdown of all the issues within the pro-industry testimony at the recent COVID vaccine cancer link hearing). Given that, I told Steve I would be happy to share it, but that I was not comfortable receiving referral fees for doing so. As such, if you use Alter AI and decide you want to upgrade to higher functionality (or just financially support them), the two letter reader discount code I was given (MD) has been set to give a portion of what you pay to charity (specifically The Vaccine Safety Research Foundation, as they do a lot of important work in this field).
Note: all of the above is in line with my policy for this newsletter to not promote products (which fortunately I do not need to do thanks to your support), so despite many requests to do so, I rarely do (only in instances where I believe one represents the best option for a particular issue I need to provide an optimal solution for, or because I feel it’s important to help create the market or supply chain for something so it can become available to the health community).
Conclusion
When modern propaganda was first developed, after the public realized it had been used on them throughout World War 1, a fierce debate (detailed here) erupted over whether engineering public consensus was compatible with democracy. One side argued crowds were irrational and that everything had grown too complex for regular citizens to understand what was best for society, so it was necessary to use propaganda to make the public follow the decisions of experts. The other (led by John Dewey, who warned that insulated experts without democratic accountability would inevitably become self-reinforcing and prone to flawed policies—as we saw throughout COVID) argued this meant we simply needed to be educated and empowered to understand those complex subjects. Since propaganda was necessary to win World War 2, the propagandists won (a trajectory Eisenhower warned against in his farewell address, cautioning that public policy could become "the captive of a scientific-technological elite"), and from there, centralized information control quietly expanded into science and medicine, eventually producing a system where propaganda compelled the public to support “the science” while being kept in the dark over the parameters of the decisions being made.
Now however, in part due to COVID breaking public trust in expert-based governance, in part due to free speech being able to rapidly disseminate online, and in part due to AI making the “domain of experts” easily accessible to the public, the pendulum at last appears to be swinging the other way on this century-old debate which has defined the course of our entire society as it is no longer possible for the propagandists to control the narrative. For example, “experts” have long been able to proclaim industry talking points with impunity, but at Johnson’s recent hearing, after Chief Medical Officer of the American Society of Clinical Oncology extolled the virtues of mRNA vaccines for cancer, Senator Johnson once again pointed out to everyone the “expert witness” was completely unfamiliar with basic technology of the vaccine and the research which refuted all of her claims—something we have not seen since the 1994 Congressional hearings that publicly exposed Big Tobacco’s CEOs and their captive scientists as the hucksters they were.
In conclusion, I hope this article was a helpful resource for you. It has been immensely frustrating to see these same tactics used again and again with impunity, and it is my sincere hope that by exposing them and making a concise summary of them available, we can help create the grassroots momentum to shift science back to a tool that advances humanity rather than one that exists to further enrich the wealthiest members of society. I sincerely thank you for your support of this newsletter, which makes it possible to get these critical messages out.
Lastly, it bears mentioning that Senator Ron Johnson has been one of the few leaders in Congress willing to use his platform to expose many of these issues. He first ran in 2010 on excessive federal spending he was concerned would “mortgage our children’s future,” then during COVID, rapidly recognized the suppression of therapeutic options would be catastrophic for both Americans and the economy, and put everything on the line to try to stop the COVID vaccine catastrophe. Given how many of these fights he’s had to wage, it is particularly disheartening that the experts policymakers sent to counter him at these hearings couldn’t even demonstrate a basic understanding of the technology they were defending, which inevitably raises the question of how well the experts who forced these policies on the public understood them either. His willingness to directly challenge credentialed witnesses on the public record, as we saw above, is precisely the kind of democratic accountability John Dewey argued was necessary to keep insulated experts honest and in check.
A recently updated index of all articles published in the Forgotten Side of Medicine (including the DMSO ones) can be viewed here. Additionally, to learn how other readers have benefitted from this publication and the community it has created, their feedback can be viewed here.
Thanks for this interesting & well done article!
Your readers will find an excellent illustration of "how to rig a clinical trial" in this in depth review of the Pfizer-BioNtech data on their COVID-19 product.
https://blog.openvaet.info/p/pfizerbiontech-c4591001-trial-audit
It illustrates offshoring, "blinding by name only", along with a few additional tricks such as not testing the product you'll release, playing on symptoms vs adverse event qualification in a context of blur definitions and faulty protocols, data frauds, and other amusements.
I am planning to send this post out on Saturday, I just had to post it before then so it would be available for Senator Johnson's hearing on this topic.